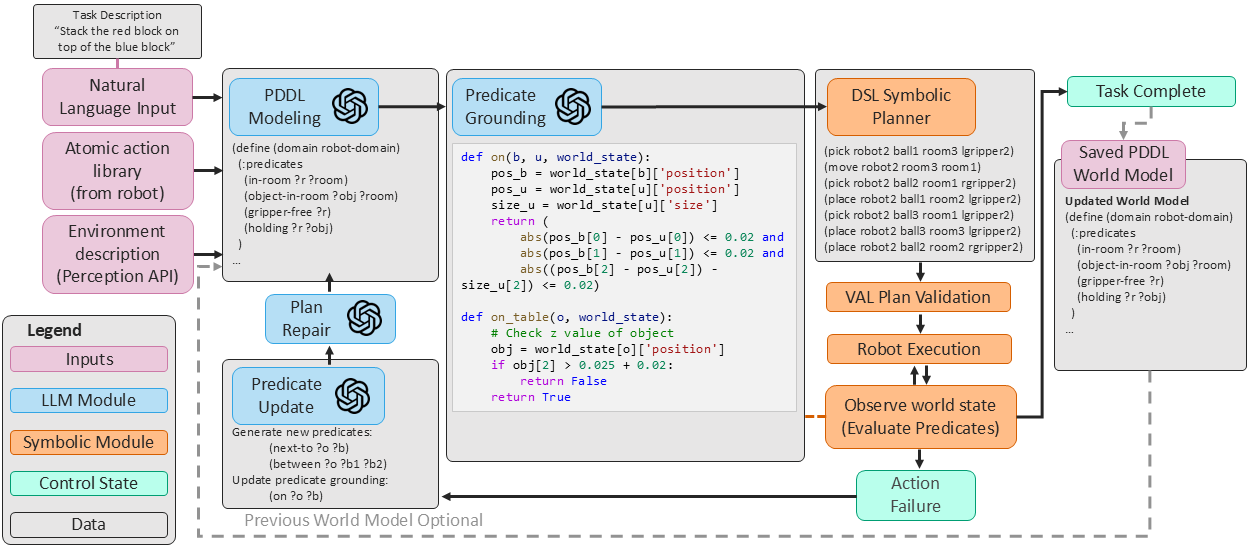
We present CLIMB, a continual
learning framework for robot task planning that leverages
foundation models and execution feedback to guide domain
model construction.
CLIMB incrementally builds a PDDL model of
its operating environment while completing tasks, creating a
set of world state predicates that function as a representation
of the causal structure present in the environment. CLIMB's
continual learning approach enables it to solve classes of
problems it has previously encountered without needing to
relearn task-specific information, endowing it with the ability
to expand its environment representation to novel problem
formulations.
We show CLIMB to be a capable zero-shot planner for simple tasks.
For complex tasks with non-obvious predicates, we demonstrate CLIMBs
ability to self-improve through iterative executiong and feedback,
resulting in superior performance once a PDDL model has been established.